Inter Domain Packet Filters based controlling of IP Spoofing.
I. INTRODUCTION
Distributed Denial of Service (DDoS) attacks pose an increasingly grave threat to the Internet, as evidenced by recent DDoS attacks mounted on both popular Internet sites and the Internet infrastructure . Alarmingly, DDoS attacks are observed on a daily basis on most of the large backbone networks . One of the factors that complicate the mechanisms for policing such attacks is IP spoofing, the act of forging the source addresses in IP packets. By masquerading as a different host, an attacker can hide its actual identity and location, rendering source-based packet filtering less effective. It has been shown that a large part of the Internet is vulnerable to IP spoofing.
Recently, there is anecdotal evidence of attackers to stage attacks utilizing bot-nets1 . In this case, since the attacks are carried out through intermediaries, i.e., the compromised “bots”, it is tempting to believe that the use of IP spoofing is less of a factor than previously. However, recent studies present evidence to the contrary and show that IP spoofing is still a commonly observed phenomenon .
It is our contention that IP spoofing will remain popular for a number of reasons. First, IP spoofing makes it harder to isolate attack traffic from legitimate traffic—packets with spoofed source addresses may appear to be from all around the Internet. Second, it presents the attacker with an easy way to insert a level of indirection, which shifts the burden to the victim; substantial effort is required to localize the source of 1 collections of hundreds or thousands of compromised hosts, “recruited” by worm or virus infection. the attack traffic. Finally, many popular attacks use IP spoofing and require the ability to forge source addresses. Man-in-the-middle attacks, such as variants of TCP hijack and DNS poisoning attacks , are carried out by the attacker masquerading as the host at the other end of a valid transaction. Reflector-based attacks use IP spoofing to masquerade as some victim host that contacts a number of hosts, resulting in the victim being flooded by replies from all these hosts . TCP SYN flood attacks rely on spoofing addresses of hosts that are unable to respond to replies . These factors indicate that IP spoofing is unlikely to decrease in the near future.
Although attackers can insert arbitrary source addresses into IP packets, they cannot, however, control the actual paths that the packets take to the destination. Based on this observation, Park and Lee proposed the route-based packet filters as a way to mitigate IP spoofing. The intuition in this scheme is that, assuming single-path routing, there is exactly one single path p(s, d) between source node s and destination node d. Hence, any packets with source address s and destination address d that appear in a router not in p(s, d) should be discarded. However, constructing a specific route-based packet filter in a node requires the knowledge of global routing decisions made by all the other nodes in the network, which is hard to reconcile on the current BGP-based Internet routing infrastructure.
The current Internet consists of approximately 15,000 network domains or autonomous systems (ASes), each of which is a logical collection of networks with common administrative control. Each AS communicates with its neighbors using the Border Gateway Protocol (BGP), the de-facto inter-domain routing protocol, to exchange information about its own networks and others that it can reach. BGP is a policy-based routing protocol in that both the selection and the propagation of the best route to reach a destination at an AS are guided by some locally defined routing policies. Given the insular nature of how policies are applied at individual ASes, it is impossible for an AS to acquire the complete knowledge of routing decisions made by all the other ASes. Hence constructing route-based packet filters as proposed in is an open challenge in the current Internet routing regime.
Inspired by the idea of route-based packet filters, we propose an Inter-Domain Packet Filter (IDPF) architecture. The IDPF architecture takes advantage of the fact that while network connectivity may imply a large number of potential paths between source and destination domains, commercial relationships between ASes act to restrict to a much smaller set the number of feasible paths that can be used to carry traffic from the source to the destination. In this paper we focus our attention on the construction of IDPFs based solely on locally exchanged BGP updates. We will investigate how other AS relationship and routing information may help further improve the performance of IDPFs in our future work.
We show that locally exchanged routing information between neighbors, i.e., BGP route updates, is sufficient to identify feasible paths and construct IDPFs. Like route-based packet filters [29], the proposed IDPFs cannot stop all spoofed packets. However, when spoofed packets are not filtered out, IDPFs can help localize the origin of attack packets to a small set of ASes, which can significantly improve the IP traceback situation [2], [13], [31], [32]. We summarize the key contributions of this paper in the following:
1)We describe how to practically construct inter-domain packet filters locally at an AS by using only the BGP route updates being exchanged between the AS and its immediate neighbors.
2)To evaluate the effectiveness of the architecture, we conduct extensive simulation studies based on AS topologies and AS paths extracted from real BGP data provided by the Route Views project . Our results show that, even with partial deployment, the architecture can proactively limit an attacker’s ability to spoof packets. When a spoofed packet cannot be stopped, IDPFs can help localize the attacker to a small number of candidate ASes, reducing the effort and increasing the accuracy of IP traceback schemes.
3)We show that unlike some protection schemes that provide intangible local benefits for deployment, the IDPF architecture provides better protection against IP spoofing based DDoS attacks on local networks, which presents incentives for network operators to deploy IDPFs.
The rest of this paper is organized as follows. We discuss related work in Section II. We provide an abstract model of BGP in Section III. Section IV presents the IDPF architecture. Section V discusses practical deployment issues. We report our simulation study of IDPFs in Section VI. We conclude the paper and discuss future work in Section VII.
II. RELATED WORK
The idea of IDPF is motivated by the work carried out by Park and Lee , which was the first effort to evaluate the relationship between topology and the effectiveness of routebased packet filtering. The authors showed that packet filters that are constructed based on the global routing information can significantly limit IP spoofing when deployed in just a small number of ASes. In this work, we extend the idea and demonstrate that filters that are built based on local BGP updates can also be effective.
Unicast reverse path forwarding (uRPF) requires that a packet is forwarded only when the interface that the packet arrives on is exactly the same used by the router to reach the source IP of the packet. If the interface does not match, the packet is dropped. While simple, the scheme is limited given that Internet routing is inherently asymmetric, i.e., the forward and reverse paths between a pair of hosts is often quite different. In Hop-Count Filtering (HCF) , each end system maintains a mapping between IP address aggregates and valid hop counts from the origin to the end system. Packets that arrive with a different hop count are suspicious and are therefore discarded or marked for further processing. In Li et al., described SAVE, a new protocol for networks to propagate valid network prefixes along the same paths that data packets will follow. Routers along the paths can thus construct the appropriate filters using the prefix and path information. Bremler-Barr and Levy proposed a spoofing prevention method (SPM) , where packets exchanged between members of the SPM scheme carry an authentication key associated with the source and destination AS domains. Packets arriving at a destination with an invalid authentication key (w.r.t. the source) are spoofed packets and are discarded.
In the Network Ingress Filtering proposal described in , traffic originating from a network is forwarded only if the source IP in the packets is from the network prefix belonging to the network. Ingress filtering primarily prevents a specific network from being used to attack others. Thus, while there is a collective social benefit in everyone deploying it, individuals do not receive direct incentives. Finally, the Bogon Route Server Project maintains a list of bogon network prefixes that are not routable on the public Internet. Examples include private RFC 1918 address blocks and unassigned address prefixes. Packets with source addresses in the bogon list are filtered out. However, this mechanism cannot filter out attack packets carrying routable but spoofed source addresses.
III. BORDER GATEWAY PROTOCOL AND AS INTERCONNECTIONS
In this section, we briefly describe a few key aspects of BGP that are relevant to this paper . To begin with, we model the AS graph of the Internet as an undirected graph G = (V, E). Each node v ∈ V corresponds to an Autonomous System (AS), and each edge e(u, v) ∈ E represents a BGP session between two neighboring ASes u, v ∈ V . To simplify the exposition, we assume that there is at most one edge between neighboring ASes.2
Each node owns one or multiple network prefixes. Nodes exchange BGP route updates, which may be announcements or withdrawals, to learn of changes in reachability to destination network prefixes. A route withdrawal, containing a list of network prefixes, indicates that the sender of the withdrawal message can no longer reach the prefixes. In contrast, a route announcement indicates that the sender knows of a path to a network prefix. The route announcement contains a list of route attributes associated with the destination networkprefix. Of particular interest to us is the path vector attribute, as path, which is the sequence of ASes that this route has been propagated over. We will use r.as path to denote the as path attribute of route r and r.prefix the destination network prefix of r. Let r.as path = hvkvk−1 . . . v1v0i. The route was originated (first announced) by node v0, which owns the address space described by r.prefix. Before arriving at node vk, the route was carried over nodes v1, v2, . . . , vk−1 in that order. For i = k, k−1, . . . , 1, we say that edge e(vi , vi−1) is on the AS path, or e(vi , vi−1) ∈ r.as path.
When there is no confusion, route r and its AS path r.as path are used interchangeably. For convenience, we consider a specific destination node d; all route announcements and withdrawals are specific to the network prefixes owned by d. For simplicity, notation d is also used to denote the network prefixes owned by the node. As a consequence, a route r that can be used to reach the network prefixes owned by destination d may simply be expressed as a route to reach destination d.
A. Policies and Route Selection
Each node only selects and propagates to neighbors a single best route to the destination, if any. BGP is a policy-based routing protocol in that both the selection and the propagation of best routes are guided by locally defined routing policies. Two distinct sets of routing policies are normally employed by a node: import policies and export policies. Neighbor-specific import policies are applied upon routes learned from neighbors, whereas neighbor-specific export policies are imposed on locally-selected best routes before they are propagated to the neighbors.
In general, import policies can affect the “desirability” of routes by modifying route attributes. Let r be a route (to destination d) received at v from node u. We denote by import(v ← u)[{r}] the possibly modified route that has been transformed by the import policies. After the routes are passed through the import policies at node v, they are stored in v’s routing table. The set of all such routes is denoted as candidateR(v, d):
candidateR(v, d) = {r : import(v ← u)[{r}] 6= {} r.prefix = d, ∀u ∈ N(v)}.
Here, N(v) is the set of v’s neighbors.
Among the set of candidate routes candidateR(v, d), node v selects a single best route to reach the destination based on a well defined procedure (see [8]). To aid in description, we shall denote the outcome of the selection procedure at node v, i.e., the best route, as bestR(v, d), which reads best route to destination d at node v.
Having selected bestR(v, d) from candidateR(v, d), v then exports the route to its neighbors after applying neighbor specific export policies. The export policies determine if a route should be forwarded to the neighbor, and if so, modify the route attributes according to the policies. We denote by export(v → u)[{r}] the route sent to neighbor u by node v, after node v applies the export policies on route r.
BGP is an incremental protocol: updates are generated only in response to network events. In the absence of any events, no route updates are triggered or exchanged between neighbors, and we say that the routing system is in a stable state. Formally,
Definition 1 (Stable Routing State): A routing system is in a stable state if all the nodes have selected a best route to reach other nodes and no route updates are generated (and propagated) by any node.


B. AS Relationships and Routing Policies
The specific routing policies that an AS employs internally is largely determined by economics: connections between ASes follow a few commercial relations. A pair of ASes can enter into one of the following arrangements.
• provider-customer: In this kind of arrangement, a customer AS pays the provider AS to carry its traffic to the rest of the Internet. This arrangement is the most common and is natural when the provider is much larger in size than the customer.
• peer-peer: In a mutual peering agreement, the ASes decide to carry traffic from each other (and their customers). This is only natural when the traffic from each other is roughly balanced. Mutual peers do not carry transit traffic for each other.
• sibling-sibling: In this type of arrangement, two ASes provide mutual transit service to each other (often as backup connectivity or for reasons of economy). Each of the two sibling ASes can be regarded as the provider of the other AS.
The rules for route export between ASes with different relationships, which are shown in Table I, have been devised . In Table I, the columns marked with r1-r4 specify the export policies employed by an AS to announce routes to providers, customers, peers, and siblings, respectively. For instance, export rule r1 instructs that an AS will announce routes to its own networks, and routes learned from customers and siblings to a provider, but it will not announce routes learned from other providers and peers to the provider. The net effect of these rules is that they limit the possible paths between each pair of ASes. The export policies described in Table I are not complete. In a few cases, ASes may choose to apply less restrictive policies to satisfy traffic engineering goals. For the moment, we assume that all ASes follow the rules r1-r4 and that each AS accepts legitimate routes exported by neighbors. More general cases will be discussed at the end of the next section.
If AS b is a provider of AS a, and AS c is a provider of AS b, we call c an indirect provider of a, and a an indirect customer of c. Indirect siblings are defined in a similar fashion. Rules r1-r4 imply that an AS will distribute the routes to direct or indirect customers/siblings to its peers and providers. If e(u, v) ∈ bestR(s, d).as path, we say that u is the best upstream neighbor of node v for traffic from node s to destination d, and denote u as u = bestU(s, d, v). We refer to an edge from a provider to a customer AS as a providerto-customer edge, an edge from a customer to provider as a customer-to-provider edge, and an edge connecting sibling (peering) ASes as sibling-to-sibling (peer-to-peer) edge. A downhill path is a sequence of edges that are either providerto-customer or sibling-to-sibling edges, and an uphill path is a sequence of edges that are either customer-to-provider or sibling-to-sibling edges. Gao established the following theorem about the candidate routes in a BGP routing table.
Theorem 1 : If all ASes set their export policies according to r1-r4, any candidate route in a BGP routing table is either (a) an uphill path, (b) a downhill path, (c) an uphill path followed by a downhill path, (d) an uphill path followed by a peer-to-peer edge, (e) a peer-to-peer edge followed by a downhill path, or (f) an uphill path followed by a peer-to-peer edge, which is followed by a downhill path.
IV. INTER DOMAIN PACKET FILTERS
In this section we discuss the intuition behind the IDPF architecture, describe how IDPFs are constructed using BGP route updates, and establish the correctness of IDPFs. After that, we discuss the case where ASes have routing policies that are less restrictive than r1-r4. We shall assume that the routing system is in the stable routing state in this section. We will discuss how IDPFs fare with network routing dynamics in the next section.
Let M(s, d) denote a packet whose source address is s (or more generally, the address belongs to network s), and destination address d. A packet filtering scheme decides whether a packet should be forwarded or dropped based on certain criteria. One example is the route-based packet filtering
Definition 2 (Route-Based Packet Filtering): Node v accepts packet M(s, d) forwarded from node u if and only if e(u, v) ∈ bestR(s, d). Otherwise, the source address of the packet is spoofed, and the packet is discarded by v.
In the context of preventing IP spoofing, an ideal packet filter should discard spoofed packets while allowing valid packets to reach the destinations. For a packet filter, forwarding valid packets is more important than dropping invalid packets. We define the correctness of a packet filter as follows.
Definition 3 (Correctness of Packet Filtering): A packet filter is correct if it does not discard packets with valid source addresses when the routing system is stable.
Clearly, the route-based packet filtering is correct, because valid packets from source s to destination d will only traverse the edges on bestR(s, d) when the routing system is stable.
A. Motivating IDPFs
Although route-based packet filtering is correct, it requires each node to have the global knowledge of bestR(s, d). In the current Internet architecture that uses BGP as the inter-domain routing protocol, such information is not available. In BGP, route selection is a local decision, i.e., s computes bestR(s,d) based on the set of routes in its routing table and preferences that an operator in AS s has defined. This information may not be available at nodes in bestR(s,d). Consequently, route-based packet filtering cannot be applied in the current BGP-based Internet routing regime.
IDPF overcomes this problem by using the information implicit in BGP updates to construct the filters. We use the following concepts to illustrate the idea of IDPF. A topological route between nodes s and d is a loop-free path between the two nodes. Topological routes are implied by the network connectivity. A topological route is a feasible route under BGP if and only if the construction of the route does not violate the export rules imposed by the commercial relationship between ASes. Formally, let feasibleR(s, d) denote the set of feasible routes from s to d, then feasibleR(s, d) can be recursively defined as follows.

where ⊕ is the concatenation operation, e.g., {hs ⊕ {habi,huvi}} = {hsabi,hsuvi}. Notice that feasibleR(s, d) contains all the routes between the pair that does not violate the export policies r1-r4. Obviously, bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d). Each of the feasible routes can potentially be a candidate route in a BGP routing table. Theorem 1 also applies to feasible routes.
Definition 4 (Feasible Upstream Neighbor): Consider a feasible route r ∈ feasibleR(s, d). If an edge e(u, v) is on the feasible route, i.e., e(u, v) ∈ r.as path, we say that node u is a feasible upstream neighbor of node v for packet M(s, d). The set of all such feasible upstream neighbors of v (for M(s, d)) is denoted as feasibleU(s, v).
The intuition behind the IDPF framework is the following. First, it is possible for a node v to infer its feasible upstream neighbors using BGP route updates. The technique to infer feasible upstream neighbors is described in the next sub-section. Since bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d), a node can only allow M(s, d) from its feasible upstream neighbors to pass and discard all other packets. Such a filtering will not discard packets with valid source addresses. Second, although network connectivity (topology) may imply a large number of topological routes between a source and destination, commercial relationship between ASes and routing policies employed by ASes act to restrict the size of feasibleR(s, d). Consider the example in Fig. 1. Figs. 2(a) and (b) present the topological routes implied by network connectivity and feasible routes constrained by routing policies between sources and destination d, respectively. In Fig. 2(b) we assume that nodes a, b, c, and d have mutual peering relationship, and that a and b are providers to s. We see that although there are 10 topological routes between source

s and destination d, we only have 2 feasible routes that are supported by routing policies. Of more importance to IDPF is that, although network topology may imply all neighbors can forward a packet allegedly from a source to a node, feasible routes constrained by routing policies help limit the set of such neighbors. As an example, let us consider the situation at node d. Given that only nodes a and b (but not c) are on the feasible routes from s to d as node d concerns, node d can infer that all packets forwarded by node c and allegedly from source s are spoofed and should be discarded.
It is clear that packet filters based on feasible routes are less powerful than those based on best routes, given that bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d). On the other hand, AS relationships normally restrict the feasible routes between a pair of source and destination to a small set, which makes feasible-route based packet filtering a practical and promising approach against IP spoofing. In the following subsection, we will present a mechanism for each node to identify the set of feasible upstream neighbors that can forward packet M(s, d) to the node, based on locally exchanged BGP updates between the node and its immediate neighbors.
B. Constructing IDPFs
The following lemma summarizes the technique to identify the feasible upstream neighbors of node v for packet M(s, d).
Lemma 1: Consider a feasible route r between source s and destination d. Let v ∈ r.as path and u be the feasible upstream neighbor of node v along r. When the routing system is stable, export(u → v)[{bestR(u, s)}] 6= {}, assuming that all ASes follow the rules r1-r4 and that each AS accepts legitimate routes exported by neighbors.
Lemma 1 states that if node u is a feasible upstream neighbor of node v for packet M(s, d), node u must have exported to node v its best route to reach the source s.
Proof: Since Theorem 1 applies to feasible routes, a feasible route can be one of the six types of paths in Theorem 1. In the following we assume the feasible route r is of type (f), i.e., an uphill path followed by a peer-to-peer edge, which is followed by a downhill path. Cases where rhas other types (a)-(e) can be similarly proved. To prove the lemma, we consider the possible positions of nodes u and v in the feasible route.
Case 1: Nodes u and v belong to the uphill path. Then node s must be an (indirect) customer or sibling of node u. From Rule r1 and the definition of indirect customers/siblings, we know u will propagate to (provider) node v the reachability information of s. Case 2: e(u, v) is the peer-to-peer edge. This case can be similarly proved as case 1 (based on Rule r3). Case 3: Nodes u and v belong to the downhill path. Let e(x, y) be the peer-to-peer edge along the feasible route r, and note that u is an (indirect) customer of y. From the proof of case 2, we know that node y learns the reachability information of s from x. From Rule r2 and the definition of indirect customers, node y will propagate the reachability information of s to node u, which will further export the reachability information of s to (customer) node v.
It is critical to note that Lemma 1 only states that a feasible upstream neighbor u of neighbor v for packet M(s, d) exports to v its best route to reach source s. Node v may choose a node other than u to reach s. Therefore, Lemma 1 does not imply the symmetry of best routes. For example, although feasible route hs . . . uv . . . di may be the best route from s to d, route hd . . . vu . . . si may not be the best route from d to s.
Relying on Lemma 1, a node can identify the feasible upstream neighbors for packet M(s, d) and conduct interdomain packet filtering as follows. Note that the filters are defined at a node specific to each neighbor. Definition 5 (Inter-Domain Packet Filtering (IDPF)): Node v will accept packet M(s, d) forwarded by a neighbor node u, if and only if export(u → v)[{bestR(u, s)}] 6= {}. 3 Otherwise, the source address of the packet must have been spoofed, and the packet should be discarded by node v.
C. Correctness of IDPF
Theorem 2: An IDPF as defined in Definition 5 is correct. Proof: Without loss of generality, consider source s, destination d, and a node v ∈ bestR(s, d).as path such
As a technical detail, the condition should be import(v ← u)[export(u → v)[{bestR(u, s)}] 6= {}. That is, not only is bestR(u, s) is exported to v by u, but also accepted by v. However, for clarity of our presentation, we ignore the effects of import policies

that v deploys an IDPF filter. In order to prove the correctness of the theorem, we need to establish that v will not discard packet M(s, d) forwarded by the best upstream neighbor u, along bestR(s, d).
Recall from the best route selection process, the best route between a source and destination is also a feasible route between the two (bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d)). Therefore, u is also a feasible upstream neighbor of node v for packet M(s, d). From Lemma 1, u must have exported to node v its best route to source s. That is export(u → v)[{bestR(u, s)}] 6= {}. From Definition 5, packet M(s, d) forwarded by node u will not be discarded by v, and we have established the correctness of the theorem.
D. Routing Policy Complications
There is an increasing trend for ASes to be multi-homed to improve the overall reliability of their Internet connectivity. In some cases, it is desirable for a multi-homed AS to use one provider as the primary or preferred provider, and treat others as back-up providers. This is illustrated in Fig 3(a). Here, ASes a and b are the providers for AS d. Among these, d wishes to use a as the primary provider and use b as a backup provider. There are several different mechanisms to achieve this goal.
A particular way to achieve this is by using so-called BGP Conditional Advertisement or Selective Announcements, as depicted in Fig. 3(b). Here, AS d announces its routes to provider a (but not to b), causing all incoming traffic to arrive via a. If the primary route through a fails, AS d will send a route to provider b and this causes subsequent inbound traffic to arrive via b. When the original primary link is restored, d withdraws its route from b, causing traffic to switch back to arriving via a. Here, note that d does not announce its route(s) to b as long as the link to a is available. However, it may still use b to send outgoing traffic. If, in this situation, b deploys an IDPF, traffic from d will be blocked.
It is important to note that selective announcement is very different from the case where a route is prohibited by r1-r4. In the present case, d chooses not to export the route even though it is allowed to (within the guidelines defined in r1-r4). This behavior cannot be supported within the IDPF framework. To be consistent with IDPF, the AS can choose alternate methods to achieve the same goal, perhaps using AS path prepending (to make the route through b less preferred) or some BGP community attributes. A stronger case can be made for this by noting that the mechanism of selective announcements has undesirable side effects. Similarly, if an AS rejects alegitimate route to a prefix exported by a neighbor that follows rules r1-r4, IDPFs may drop packets from that prefix.
If for some reason, an AS u chooses to employ selective announcements, i.e., it chooses not to announce a route to a neighbor (even though it can under r1-r4), we suggest the following rule to be applied at u:
r5. Restricted conditional advertisement policy: If an AS can announce a route (originated by a specific network) to a neighbor, but chooses not to do so, then the AS must not forward any traffic from the network to the particular neighbor.
If each AS on the Internet follows the routing policies r1- r5, we can establish the correctness of IDPFs as defined in Definition 5 on the Internet. The proof is similar to the one of Lemma 1 and Theorem 2 and we omit it here.
V. PRACTICAL DEPLOYMENT ISSUES OF IDPFS
A. Incremental Deployment
From the description in Section IV, it should be clear that the IDPFs can be deployed independently in each AS. IDPFs are deployed at the border routers, so that IP packets can be inspected before they enter the network. We term border routers that are IDPF enabled as “IDPF nodes”. An IDPF node is required to track the destination network prefixes announced by each neighbor. Typically, we expect that BGP speaking routers will support IDPF. In the case that an IDPF node is not a BGP router, it needs to obtain the corresponding prefix announcement information from the BGP speaking routers.
When a packet arrives at an IDPF node, it needs to be associated with the specific neighbor that forwarded the packet. Subsequently, the IDPF matches the address against the set of prefixes announced by the specific neighbor. If a matching prefix exists, the packet is forwarded to the immediate destination in the AS or further routed towards the final destination. Otherwise, it is dropped by the IDPF node at the ingress of the network.
B. Handling Routing Dynamics
In the discussion so far, we have assumed that the AS graph is a static structure. However, in reality, the graph does change, triggering the generation of BGP updates and altering the paths that ASes use to reach each other. In this subsection, we examine how routing dynamics may affect the operation of IDPFs. We consider two different types of routing dynamics: 1) those caused by network failures; 2) and those caused by the creation of a new network (or recovery from a fail-down network event). Routing dynamics caused by routing policy changes can be similarly addressed and we omit them here.
Note that while filters are constructed based on route updates received from neighbors, they are completely oblivious to the specifics of the announced route. Moreover, the set of feasible upstream neighbors will not admit more members in the period of routing convergence following a network failure (since AS relationship is static). Hence, for the first type of routing dynamics, we can rule out the possibility that the filter will block a valid IP packet. We illustrate this as follows:
consider an IDPF enabled AS v that is on the best route from s to d. Let u = bestU(s, d, v), and let U = feasibleU(s, v). A link or router failure between u and s can have three outcomes: 1) AS u can still reach AS s, and u is still chosen to be the best upstream neighbor for packet M(s, d), i.e, u = bestU(s, d, v). In this situation, although u may explore and announce multiple routes to v during the path exploration process [7], the filtering function of v is unaffected. 2) AS u is no longer the best upstream neighbor for packet M(s, d); another feasible upstream neighbor u 0 ∈ U can reach AS s and is instead chosen to be the new best upstream neighbor (for M(s, d)). Now, both u and u 0 may explore multiple routes; however, since u 0 has already announced a route (about s) to v, the IDPF at v can correctly filter (i.e., accept) packet M(s, d) forwarded from u 0 . 3) No feasible upstream neighbors can reach s. Consequently, AS v will also not be able to reach s, and v will no longer be on the best route between s and d. No new packet M(s, d) should be sent through v.
Yet another concern of routing dynamics relates to how newly connected network (or a network recovered from a faildown event) will be affected. In general, a network may start sending data immediately following the announcement of a (new) prefix, even before the route has had time to propagate to the rest of the Internet. In the time that it takes for the route to be propagated, some packets (from this prefix) maybe discarded by some IDPFs if the reachability information has not yet propagated to them. However, the mitigating factor here is that in contrast to the long convergence delay that follows failure, reachability for the new prefix will be distributed far more speedily. In general, the time taken for such new prefix information to reach an IDPF is proportional to the shortest AS path between the IDPF and the originator of the prefix and independent of the number of alternate paths between the two. Previous work has established this bound to be O(L), L being the diameter of the AS graph [7], [22]. We believe that in the short timescales we are discussing, it is acceptable for IDPFs to potentially behave incorrectly, i.e. discarding valid packets originated from the new network prefix, before the corresponding BGP announcements reach the IDPFs. Similarly, during this short time of period, IDPFs may fail to discard spoofed attack packets. However, given that most DDoS attacks require a persistent train of packets to be directed at a victim, we believe this behavior of IDPFs for failing to discard spoofed packets should also be acceptable.
C. Other Issues
In the rest of this section we briefly discuss a few other properties of the IDPF framework.
By deploying IDPFs, an AS constrains the set of packets that a neighbor can forward to the AS. Specifically, a neighbor can only successfully forward a packet M(s, d) to the AS after it announces the reachability information of s. All other packets are identified to carry spoofed source addresses and discarded at the border router of the AS. In the worst case, even if only a single AS deploys IDPF and spoofed IP packets can get routed all the way to the AS in question, using an IDPF perimeter makes it likely that spoofed packets will be identified, and blocked, at the perimeter. Clearly, if the AS is well connected, launching a DDoS attack upon the perimeter itself takes a lot more effort than targeting individual hosts and services within the AS. In contrast, ASes that do not deploy IDPF offer relatively little protection to the internal hosts and services. Therefore, an AS has direct benefits to deploy IDPFs. In general, by deploying IDPFs, an AS can also protect other ASes to which the AS transports traffic, in particular, the customer ASes. This can be similarly understood that, an IDPF node limits the set of packets forwarded by a neighbor and destined for a customer of the AS.
The destination address d in a packet M(s, d) plays no role in an IDPF node’s filtering decision (Definition 5). We make this design decision for the following reasons: 1) We assume that a node u will forward a packet M(s, d) to node v only if bestR(v, d) has been exported to u by v. 2) By constructing filtering tables based on source address alone (rather than both source and destination addresses), per-neighbor space complexity for an IDPF node is reduced from O(N2 ) to O(N), where N = |V | is the number of nodes in the graph (the route-based scheme can achieve the same complexity bound.
An IDPF may not be able to catch all spoofed packets forwarded by a neighbor. Note that an IDPF allows all the feasible upstream neighbors for packet M(s, d) to send the packet. However, in reality, exactly one of them will lie on bestR(s, d) and forward M(s, d). On the other hand, it is worth noting that an attacker in a best upstream neighbor for packet M(s, d) can always spoof the source address s; therefore, route-based packet filters also cannot catch all spoofed packets. In the next section, we will conduct simulation studies to compare the performance of route-based packet filtering with that of the IDPF framework.
VI. PERFORMANCE STUDIES
In this section we first discuss the objectives of our performance studies and the corresponding performance metrics. We then describe the data sets and specific settings used in the simulation studies. Detailed results obtained from simulations are presented at the end of this section.
A. Objectives and Metrics
We evaluate the effectiveness of IDPFs in controlling IP spoofing based DDoS attacks from two complementary perspectives [29]. First, we wish to understand how effective the IDPFs are in proactively limiting (if not preventing) the capability of an attacker to spoof addresses of ASes other than his own. Our approach does not provide complete protection and spoofed packets may still be transmitted. Thus the complementary, reactive view is also important; we study how the deployed IDPFs can improve IP traceback effectiveness by localizing the actual source of spoofed packets. A third dimension of our simulation studies concerns the issue of incentive, i.e., how an individual AS will benefit from deploying IDPF on its routers.
A family of performance metrics was introduced in [29], and we include them in our own study. Given any pair of ASes, say a and t, Sa,t is the set of ASes, from which an attacker in AS a can forge addresses to attack t. For any pair of ASes, s and t, Cs,t is the set of ASes, from which attackers can attack t using addresses belonging to s, without such packets being filtered before they reach t.
To establish a contrast: Sa,t quantifies the pool of IP addresses that may be forged by an attacker in a to send packets to t without being stopped. On the hand, Cs,t is defined from the victim, i.e., AS t’s perspective. This quantifies the size of the set of ASes that can forge an address belonging to s in sending packets to t without being discarded along the way. Thus the latter is a measure of the effort required, at AS t, to trace the packets to the actual source (there are |Cs,t| locations that the packet could have originated from).
1) Proactive Prevention Metrics: Given the AS graph G = (V, E), we define the prevention metric from the point of view of the victim as follows:

φ1(τ ), redefined from [29], denotes the proportion of ASes that satisfy the following property: if an arbitrary attacker intends to generate spoofed packets, he can successfully use the IP addresses of at most τ ASes (note that this includes the attacker’s own AS). Thus, φ1(τ ) represents the effectiveness of IDPFs in protecting ASes against spoofing-based DDoS attacks. For instance, φ1(1), which should be read as the fraction of ASes that can be attacked with packets from at most 1 AS, describes the immunity to all spoofing based attacks.4 Next, we define a metric from the attacker’s perspective. Given G = (V, E), φ2(τ ), defined in [29], describes the fraction of ASes from which an attacker can forge addresses belonging to at most τ ASes (including the attacker’s own), in attacking any other ASes in the graph.

Intuitively, φ2(τ ) is the strength of IDPFs in limiting the spoofing capability of an arbitrary attacker. For instance, φ2(1) quantifies the fraction of ASes from which an attacker cannot spoof any address other than his own.
2) Reactive IP Trace back Metrics: To evaluate the effectiveness of IDPFs in reducing the IP trace back effort, i.e., the act of determining the true origin of spoofed packets, ψ1(τ ) is defined in, which is the proportion of ASes being attacked that can localize the true origin of an attack packet to be within τ ASes.

For instance, ψ1(1) is simply the fraction of ASes, which when attacked, can correctly identify the (single) source AS that the spoofed packet was originated from.
3) Incentives to Deploy IDPF: To formally study the gains that ASes might accrue by deploying IDPFs on their border routers, we introduce a related set of metrics, φ¯ 1(τ ), φ¯ 2(τ ), and ψ¯ 1(τ ). Let T denote the set of ASes that support IDPFs.

Note that these are similar to the metrics defined earlier, i.e., φ1(τ ), φ2(τ ), and ψ1(τ ), respectively. However, we restrict the destinations to the set of IDPF enabled ASes, rather than the entire population of ASes.
B. Data Sets
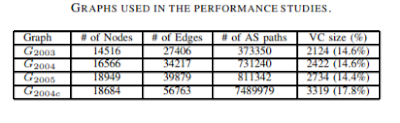
In order to evaluate the effectiveness of IDPFs, we construct four AS graphs from the BGP data archived by the Oregon Route Views Project [27]. The first three graphs, denoted G2003, G2004, and G2005 are constructed from single routing table snapshots (taken from the first day in each of the years). While these provide an indication of the evolutionary trends in the growth of the Internet AS graph, they offer only a partial view of the existing connectivity [17]. In order to obtain a more comprehensive picture, similar to [14], [18], we construct G2004c by combining G2003 and an entire year of BGP updates between G2003 and G2004. Note that the Slammer worm attack [25], which caused great churn of the Internet routing system, occurred during this period of time. This had the side effect of exposing many more edges and paths than would be normally visible.
Table II summarizes the properties of the four graphs. In the table we enumerate the number of nodes, edges, and AS paths that we could extract from the datasets. We also include the size of the vertex cover for the graph corresponding to individual datasets (the construction is described later). From the table we see that, G2004c has about 22000 more edges compared to G2004, or a 65.9% increase. Also, the number of observed AS paths in G2004c is an order of magnitude more than the observed paths in the G2004 data.
C. Inferring Feasible Upstream Neighbors
In order for each AS to determine the feasible upstream neighbors for packets from source to destination, we also
augment each graph with the corresponding AS paths used for constructing the graph [27]. We infer the set of feasible upstream neighbors for a packet at an AS as follows. In general, if we observe an AS path hvk, vk−1, . . . , v0i associated with prefix P, we take this as an indication that vi announced the route for P to vi+1, i.e., vi ∈ feasibleU(P, vi+1), for i = 0, 1, . . . , k − 1
D. Settings of Performance Studies
1) Routing: Given an AS graph G = (V, E) and a subset of nodes T ⊆ V deploying the IDPFs, the route that a packet takes from source node s to destination node t will determine the IDPFs that the packet will encounter on the way. Consequently, in order to compute the described performance metrics, we require the exact routes that will be taken between any pairs of nodes. Unfortunately, there is simply no easy way to get this knowledge accurately. In this paper, as a heuristic, we simply use the shortest path on G. When there are multiple candidates, we arbitrarily select one of them. Note that this knowledge, i.e., the best path from an AS to another, is only required in the simulation studies to determine the IDPFs that a packet may encounter on the way from source to destination. It is not required in the construction of the IDPFs. As a consequence, in addition to AS paths, we also include the selected shortest path as a feasible route, if it has not been described in the routing updates observed.
2) Selecting IDPF Nodes:
Given a graph G = (V, E), we select the filter set, i.e., nodes in T to support IDPF in one of two ways. The first one, denoted V C, aggressively selects the nodes with the highest degree until nodes in T form a vertex cover of G. In the second method, Rnd, we randomly (uniformly) choose the nodes from V until a desirable proportion of nodes are chosen. In the studies that we describe the target proportions are 30% and 50%. The corresponding sets are labeled Rnd30 and Rnd50, respectively.
3) BGP Updates vs. Precise Routing:
So far we have assumed that the precise global routing information is not available at IDPFs, and they rely on BGP update messages to infer if a packet originated from a prefix can be forwarded by a specific neighbor. To exactly understand any improvement we gain from accurate knowledge of the best route between ASes, we compare performance in two settings. In the first, BGP updates, ASes only use the AS paths (as described above) to construct the filters. In the second, precise routing, which is identical to the route-based packet filtering in, each node in the graph knows the best route for all other pairs and uses that single best route in the filter construction.
4) Network Ingress Filtering: Network ingress filtering is a mechanism that prevents an AS, where the mechanism is deployed, from being used to stage IP spoofing based attacks against host(s) in a different AS. It is reasonable to assume that ASes that deploy IDPFs, being security conscious and network-savvy, will also implement ingress filtering. However, this cannot always taken to be the case, and towards the end of this section, we discuss the case when ingress filtering is not deployed anywhere.
E. Results of Performance Studies
The studies are performed with the Distributed Packet Filtering (dpf) simulation tool . We extended dpf to support our own filter construction based on BGP updates. Before we describe the simulation results in detail, we briefly summarize the salient findings.
• Although it is difficult to completely protect networks from spoofing-based DDoS attacks (unless filters are near-universally deployed by ASes on the Internet), IDPFs can significantly limit the spoofing capability of an attacker. For example, with V C IDPF coverage, an attacker in more than 80% of ASes cannot successfully launch any spoofing-based attack on the Internet. Moreover, with the same configuration, the AS under attack can localize the true origin of an attack packet to be within 28 ASes, therefore, greatly reducing the effort of IP traceback.
• Network ingress filtering helps improve the performance of IDPFs. However, even without network ingress filtering being deployed in any ASes, an attacker still cannot launch any spoofing-based attacks from within more than 60% of ASes. Moreover, the AS under attack

can localize the true origin of an attack packet to be within 87 ASes.
ASes (and their customers) are better protected by deploying IDPFs compared to the ones that do not. For example, while only about 5% of all nodes on the Internet cannot be attacked by attackers that can spoof IP addresses of more than 6000 nodes, that percentage becomes higher than 11% among the nodes that support IDPFs (with Rnd30 IDPF coverage).
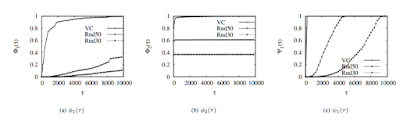
1) IDPFs with BGP Updates: Fig. 4(a) presents the values of φ1(τ ) for three different ways of selecting the IDPF node on the G2004c graph: vertex cover (V C) and random covers (Rnd50 and Rnd30). Note that φ1(τ ) indicates the proportion of nodes that may be attacked by an attacker that can spoof the IP addresses of at most τ nodes. In particular, φ1(1) is the portion of nodes that are immune to any spoofingbased attacks. Unfortunately, it is zero for all three covers. Moreover, as shown in Fig. 6, unless nearly all nodes support IDPFs, we cannot completely protect a network from spoofingbased attacks. (This is the case for all the simulations we conducted for this work.) As a consequence, instead of trying to completely protect ASes from spoofing-based attacks, we should focus on limiting the spoofing capability of attackers, which is indeed feasible as we shall show shortly. The figure also shows that the placement of IDPFs plays a key role in the effectiveness of IDPFs in controlling spoofing-based attacks. For example, with only 17.8% of nodes supporting IDPFs, VC outperforms both Rnd30 and Rnd50, although they recruit a larger number of nodes supporting IDPFs. In general, it is more preferable for nodes with large degrees (such as big ISPs) to deploy IDPFs. Fig. 5(a) shows φ1(τ ) for the graphs from 2003 to 2005 (including G2004c). We see that, overall, similar trends hold for all the years examined. However, it is worth noting that G2004c performs worse than G2004. This is because G2004c contains more edges and more AS paths by incorporating one-year BGP updates.
φ2(τ ) illustrates how effective IDPFs are in limiting the spoofing capability of attackers. In particular, φ2(1) is the proportion of nodes from which an attacker cannot launch any spoofing-based attacks against any other nodes. Fig. 4(b) shows that IDPFs are very effective in this regard. For G2004c, φ2(1) = 0.807857, 0.592325, 0.361539, for V C, Rnd50, and Rnd30, respectively. Similar trends hold for all the years examined (Fig. 5(b)).
Recall that ψ1(τ ) indicates the proportion of nodes that, under attack by packets with a source IP address, can pinpoint the true origin of the packets to be within at most τ nodes. Fig. 4(c) shows that all nodes can localize the true origin of an arbitrary attack packet to be within a small number of candidate nodes (28 nodes, see Fig. 5(c)) for the V C cover. For the other two, i.e., Rnd30 and Rnd50, the ability of nodes

to pinpoint the true origin is greatly reduced. From Fig. 5(c) we also see that G2003, G2004, and G2005 can all pinpoint the true origin of attack packets to be within 10 nodes. However, it is important to note that such graphs are less-complete representations of the Internet topology compared to G2004c.
2) Impacts of Precise Routing Information: In this section we study the impact of the precise global routing information on the performance of IDPFs. As shown in Fig. 7, the availability of the precise routing information between any pair of source and destination only slightly improves the performance of IDPFs in comparison to the case where BGP update information is used. For example, while about 84% of nodes cannot be used by attackers to launch any spoofing-based attacks by relying on the precise routing information, there are still about 80% of ASes where an attacker cannot launch any such attacks by solely relying on BGP update information. Similarly, by only relying on BGP update information, an arbitrary AS can still pinpoint the true origin of an attack packet be within 28 ASes, compared to 7 if precise global routing information is available.
ble for the slow deployment of network ingress filtering is that the deployment of such filtering function directly benefits the rest of the Internet instead of the network that supports it. In contrast, networks supporting IDPFs are better protected than the ones that do not (Fig. 8). In Fig. 8(a) we show the values of φ¯ 1(τ ) (curve marked with IDPF Nodes) and φ1(τ ) (marked with All Nodes). From the figure we see that while only about 5% of all nodes on the Internet cannot be attacked by attackers that can spoof IP addresses of more than 6000 nodes, that percentage increases to higher than 11% among the nodes that support IDPFs. Moreover, as the value of τ increases, the difference between the two enlarges. Similarly, while only about 18% of all nodes on the Internet can pinpoint the true origin of an attack packet to be within 5000 nodes, more than 33% of nodes supporting IDPFs can do so (Fig. 8(b)).
compares the spoofing capability of attackers in attacking a general node on the Internet and that supporting IDPFs. We see that networks supporting IDPFs only gain slightly in this perspective. This can be understood by noting that, by deploying IDPFs, an AS not only protects itself, but also those to whom the AS transports traffic.
4) Impacts of Network Ingress Filtering: So far we have assumed that networks supporting IDPFs also employ network ingress packet filtering [16], i.e., attackers cannot launch spoofing-based attacks from within such networks. In this section we examine the implications of this assumption.

From Fig. 12 we see that ingress packet filtering has only modest impacts on the effectiveness of IDPFs in limiting the spoofing capability of attackers. For example, without network ingress filtering, we still have more than 60% of nodes from which an attacker cannot launch any spoofing-based attacks, compared to 80% when ingress filtering is enabled at nodes supporting IDPFs. As shown in Fig. 13, the impact of networkingress filtering on the effectiveness of IDPFs in terms of reactive IP traceback is also small. Without ingress filtering, an arbitrary node can pinpoint the true origin of an attack packet to be within 87 nodes, compared to 28 when networks supporting IDPFs also employ ingress filtering.
VII. CONCLUSION AND FUTURE WORK
In this paper we proposed and studied an inter-domain packet filter (IDPF) architecture as an effective countermeasure to the IP spoofing-based DDoS attacks. IDPFs rely on BGP update messages exchanged between neighboring ASes on the Internet to infer the validity of source address of a packet forwarded by a neighbor. We showed that IDPFs can be easily deployed on the current BGP-based Internet routing architecture. Our simulation results showed that, even with partial deployment on the Internet, IDPFs can significantly limit the spoofing capability of attackers; moreover, they also help localize the actual origin of an attack packet to be within a small number of candidate networks. In addition, IDPFs also provide adequate local incentives for network operators to deploy them. As future work, we plan to study the cost introduced by the filtering function on the forwarding path of packets. We also plan to investigate how other AS relationship and routing information may help to further improve the performance of IDPFs.
Distributed Denial of Service (DDoS) attacks pose an increasingly grave threat to the Internet, as evidenced by recent DDoS attacks mounted on both popular Internet sites and the Internet infrastructure . Alarmingly, DDoS attacks are observed on a daily basis on most of the large backbone networks . One of the factors that complicate the mechanisms for policing such attacks is IP spoofing, the act of forging the source addresses in IP packets. By masquerading as a different host, an attacker can hide its actual identity and location, rendering source-based packet filtering less effective. It has been shown that a large part of the Internet is vulnerable to IP spoofing.
Recently, there is anecdotal evidence of attackers to stage attacks utilizing bot-nets1 . In this case, since the attacks are carried out through intermediaries, i.e., the compromised “bots”, it is tempting to believe that the use of IP spoofing is less of a factor than previously. However, recent studies present evidence to the contrary and show that IP spoofing is still a commonly observed phenomenon .
It is our contention that IP spoofing will remain popular for a number of reasons. First, IP spoofing makes it harder to isolate attack traffic from legitimate traffic—packets with spoofed source addresses may appear to be from all around the Internet. Second, it presents the attacker with an easy way to insert a level of indirection, which shifts the burden to the victim; substantial effort is required to localize the source of 1 collections of hundreds or thousands of compromised hosts, “recruited” by worm or virus infection. the attack traffic. Finally, many popular attacks use IP spoofing and require the ability to forge source addresses. Man-in-the-middle attacks, such as variants of TCP hijack and DNS poisoning attacks , are carried out by the attacker masquerading as the host at the other end of a valid transaction. Reflector-based attacks use IP spoofing to masquerade as some victim host that contacts a number of hosts, resulting in the victim being flooded by replies from all these hosts . TCP SYN flood attacks rely on spoofing addresses of hosts that are unable to respond to replies . These factors indicate that IP spoofing is unlikely to decrease in the near future.
Although attackers can insert arbitrary source addresses into IP packets, they cannot, however, control the actual paths that the packets take to the destination. Based on this observation, Park and Lee proposed the route-based packet filters as a way to mitigate IP spoofing. The intuition in this scheme is that, assuming single-path routing, there is exactly one single path p(s, d) between source node s and destination node d. Hence, any packets with source address s and destination address d that appear in a router not in p(s, d) should be discarded. However, constructing a specific route-based packet filter in a node requires the knowledge of global routing decisions made by all the other nodes in the network, which is hard to reconcile on the current BGP-based Internet routing infrastructure.
The current Internet consists of approximately 15,000 network domains or autonomous systems (ASes), each of which is a logical collection of networks with common administrative control. Each AS communicates with its neighbors using the Border Gateway Protocol (BGP), the de-facto inter-domain routing protocol, to exchange information about its own networks and others that it can reach. BGP is a policy-based routing protocol in that both the selection and the propagation of the best route to reach a destination at an AS are guided by some locally defined routing policies. Given the insular nature of how policies are applied at individual ASes, it is impossible for an AS to acquire the complete knowledge of routing decisions made by all the other ASes. Hence constructing route-based packet filters as proposed in is an open challenge in the current Internet routing regime.
Inspired by the idea of route-based packet filters, we propose an Inter-Domain Packet Filter (IDPF) architecture. The IDPF architecture takes advantage of the fact that while network connectivity may imply a large number of potential paths between source and destination domains, commercial relationships between ASes act to restrict to a much smaller set the number of feasible paths that can be used to carry traffic from the source to the destination. In this paper we focus our attention on the construction of IDPFs based solely on locally exchanged BGP updates. We will investigate how other AS relationship and routing information may help further improve the performance of IDPFs in our future work.
We show that locally exchanged routing information between neighbors, i.e., BGP route updates, is sufficient to identify feasible paths and construct IDPFs. Like route-based packet filters [29], the proposed IDPFs cannot stop all spoofed packets. However, when spoofed packets are not filtered out, IDPFs can help localize the origin of attack packets to a small set of ASes, which can significantly improve the IP traceback situation [2], [13], [31], [32]. We summarize the key contributions of this paper in the following:
1)We describe how to practically construct inter-domain packet filters locally at an AS by using only the BGP route updates being exchanged between the AS and its immediate neighbors.
2)To evaluate the effectiveness of the architecture, we conduct extensive simulation studies based on AS topologies and AS paths extracted from real BGP data provided by the Route Views project . Our results show that, even with partial deployment, the architecture can proactively limit an attacker’s ability to spoof packets. When a spoofed packet cannot be stopped, IDPFs can help localize the attacker to a small number of candidate ASes, reducing the effort and increasing the accuracy of IP traceback schemes.
3)We show that unlike some protection schemes that provide intangible local benefits for deployment, the IDPF architecture provides better protection against IP spoofing based DDoS attacks on local networks, which presents incentives for network operators to deploy IDPFs.
The rest of this paper is organized as follows. We discuss related work in Section II. We provide an abstract model of BGP in Section III. Section IV presents the IDPF architecture. Section V discusses practical deployment issues. We report our simulation study of IDPFs in Section VI. We conclude the paper and discuss future work in Section VII.
II. RELATED WORK
The idea of IDPF is motivated by the work carried out by Park and Lee , which was the first effort to evaluate the relationship between topology and the effectiveness of routebased packet filtering. The authors showed that packet filters that are constructed based on the global routing information can significantly limit IP spoofing when deployed in just a small number of ASes. In this work, we extend the idea and demonstrate that filters that are built based on local BGP updates can also be effective.
Unicast reverse path forwarding (uRPF) requires that a packet is forwarded only when the interface that the packet arrives on is exactly the same used by the router to reach the source IP of the packet. If the interface does not match, the packet is dropped. While simple, the scheme is limited given that Internet routing is inherently asymmetric, i.e., the forward and reverse paths between a pair of hosts is often quite different. In Hop-Count Filtering (HCF) , each end system maintains a mapping between IP address aggregates and valid hop counts from the origin to the end system. Packets that arrive with a different hop count are suspicious and are therefore discarded or marked for further processing. In Li et al., described SAVE, a new protocol for networks to propagate valid network prefixes along the same paths that data packets will follow. Routers along the paths can thus construct the appropriate filters using the prefix and path information. Bremler-Barr and Levy proposed a spoofing prevention method (SPM) , where packets exchanged between members of the SPM scheme carry an authentication key associated with the source and destination AS domains. Packets arriving at a destination with an invalid authentication key (w.r.t. the source) are spoofed packets and are discarded.
In the Network Ingress Filtering proposal described in , traffic originating from a network is forwarded only if the source IP in the packets is from the network prefix belonging to the network. Ingress filtering primarily prevents a specific network from being used to attack others. Thus, while there is a collective social benefit in everyone deploying it, individuals do not receive direct incentives. Finally, the Bogon Route Server Project maintains a list of bogon network prefixes that are not routable on the public Internet. Examples include private RFC 1918 address blocks and unassigned address prefixes. Packets with source addresses in the bogon list are filtered out. However, this mechanism cannot filter out attack packets carrying routable but spoofed source addresses.
III. BORDER GATEWAY PROTOCOL AND AS INTERCONNECTIONS
In this section, we briefly describe a few key aspects of BGP that are relevant to this paper . To begin with, we model the AS graph of the Internet as an undirected graph G = (V, E). Each node v ∈ V corresponds to an Autonomous System (AS), and each edge e(u, v) ∈ E represents a BGP session between two neighboring ASes u, v ∈ V . To simplify the exposition, we assume that there is at most one edge between neighboring ASes.2
Each node owns one or multiple network prefixes. Nodes exchange BGP route updates, which may be announcements or withdrawals, to learn of changes in reachability to destination network prefixes. A route withdrawal, containing a list of network prefixes, indicates that the sender of the withdrawal message can no longer reach the prefixes. In contrast, a route announcement indicates that the sender knows of a path to a network prefix. The route announcement contains a list of route attributes associated with the destination networkprefix. Of particular interest to us is the path vector attribute, as path, which is the sequence of ASes that this route has been propagated over. We will use r.as path to denote the as path attribute of route r and r.prefix the destination network prefix of r. Let r.as path = hvkvk−1 . . . v1v0i. The route was originated (first announced) by node v0, which owns the address space described by r.prefix. Before arriving at node vk, the route was carried over nodes v1, v2, . . . , vk−1 in that order. For i = k, k−1, . . . , 1, we say that edge e(vi , vi−1) is on the AS path, or e(vi , vi−1) ∈ r.as path.
When there is no confusion, route r and its AS path r.as path are used interchangeably. For convenience, we consider a specific destination node d; all route announcements and withdrawals are specific to the network prefixes owned by d. For simplicity, notation d is also used to denote the network prefixes owned by the node. As a consequence, a route r that can be used to reach the network prefixes owned by destination d may simply be expressed as a route to reach destination d.
A. Policies and Route Selection
Each node only selects and propagates to neighbors a single best route to the destination, if any. BGP is a policy-based routing protocol in that both the selection and the propagation of best routes are guided by locally defined routing policies. Two distinct sets of routing policies are normally employed by a node: import policies and export policies. Neighbor-specific import policies are applied upon routes learned from neighbors, whereas neighbor-specific export policies are imposed on locally-selected best routes before they are propagated to the neighbors.
In general, import policies can affect the “desirability” of routes by modifying route attributes. Let r be a route (to destination d) received at v from node u. We denote by import(v ← u)[{r}] the possibly modified route that has been transformed by the import policies. After the routes are passed through the import policies at node v, they are stored in v’s routing table. The set of all such routes is denoted as candidateR(v, d):
candidateR(v, d) = {r : import(v ← u)[{r}] 6= {} r.prefix = d, ∀u ∈ N(v)}.
Here, N(v) is the set of v’s neighbors.
Among the set of candidate routes candidateR(v, d), node v selects a single best route to reach the destination based on a well defined procedure (see [8]). To aid in description, we shall denote the outcome of the selection procedure at node v, i.e., the best route, as bestR(v, d), which reads best route to destination d at node v.
Having selected bestR(v, d) from candidateR(v, d), v then exports the route to its neighbors after applying neighbor specific export policies. The export policies determine if a route should be forwarded to the neighbor, and if so, modify the route attributes according to the policies. We denote by export(v → u)[{r}] the route sent to neighbor u by node v, after node v applies the export policies on route r.
BGP is an incremental protocol: updates are generated only in response to network events. In the absence of any events, no route updates are triggered or exchanged between neighbors, and we say that the routing system is in a stable state. Formally,
Definition 1 (Stable Routing State): A routing system is in a stable state if all the nodes have selected a best route to reach other nodes and no route updates are generated (and propagated) by any node.


B. AS Relationships and Routing Policies
The specific routing policies that an AS employs internally is largely determined by economics: connections between ASes follow a few commercial relations. A pair of ASes can enter into one of the following arrangements.
• provider-customer: In this kind of arrangement, a customer AS pays the provider AS to carry its traffic to the rest of the Internet. This arrangement is the most common and is natural when the provider is much larger in size than the customer.
• peer-peer: In a mutual peering agreement, the ASes decide to carry traffic from each other (and their customers). This is only natural when the traffic from each other is roughly balanced. Mutual peers do not carry transit traffic for each other.
• sibling-sibling: In this type of arrangement, two ASes provide mutual transit service to each other (often as backup connectivity or for reasons of economy). Each of the two sibling ASes can be regarded as the provider of the other AS.
The rules for route export between ASes with different relationships, which are shown in Table I, have been devised . In Table I, the columns marked with r1-r4 specify the export policies employed by an AS to announce routes to providers, customers, peers, and siblings, respectively. For instance, export rule r1 instructs that an AS will announce routes to its own networks, and routes learned from customers and siblings to a provider, but it will not announce routes learned from other providers and peers to the provider. The net effect of these rules is that they limit the possible paths between each pair of ASes. The export policies described in Table I are not complete. In a few cases, ASes may choose to apply less restrictive policies to satisfy traffic engineering goals. For the moment, we assume that all ASes follow the rules r1-r4 and that each AS accepts legitimate routes exported by neighbors. More general cases will be discussed at the end of the next section.
If AS b is a provider of AS a, and AS c is a provider of AS b, we call c an indirect provider of a, and a an indirect customer of c. Indirect siblings are defined in a similar fashion. Rules r1-r4 imply that an AS will distribute the routes to direct or indirect customers/siblings to its peers and providers. If e(u, v) ∈ bestR(s, d).as path, we say that u is the best upstream neighbor of node v for traffic from node s to destination d, and denote u as u = bestU(s, d, v). We refer to an edge from a provider to a customer AS as a providerto-customer edge, an edge from a customer to provider as a customer-to-provider edge, and an edge connecting sibling (peering) ASes as sibling-to-sibling (peer-to-peer) edge. A downhill path is a sequence of edges that are either providerto-customer or sibling-to-sibling edges, and an uphill path is a sequence of edges that are either customer-to-provider or sibling-to-sibling edges. Gao established the following theorem about the candidate routes in a BGP routing table.
Theorem 1 : If all ASes set their export policies according to r1-r4, any candidate route in a BGP routing table is either (a) an uphill path, (b) a downhill path, (c) an uphill path followed by a downhill path, (d) an uphill path followed by a peer-to-peer edge, (e) a peer-to-peer edge followed by a downhill path, or (f) an uphill path followed by a peer-to-peer edge, which is followed by a downhill path.
IV. INTER DOMAIN PACKET FILTERS
In this section we discuss the intuition behind the IDPF architecture, describe how IDPFs are constructed using BGP route updates, and establish the correctness of IDPFs. After that, we discuss the case where ASes have routing policies that are less restrictive than r1-r4. We shall assume that the routing system is in the stable routing state in this section. We will discuss how IDPFs fare with network routing dynamics in the next section.
Let M(s, d) denote a packet whose source address is s (or more generally, the address belongs to network s), and destination address d. A packet filtering scheme decides whether a packet should be forwarded or dropped based on certain criteria. One example is the route-based packet filtering
Definition 2 (Route-Based Packet Filtering): Node v accepts packet M(s, d) forwarded from node u if and only if e(u, v) ∈ bestR(s, d). Otherwise, the source address of the packet is spoofed, and the packet is discarded by v.
In the context of preventing IP spoofing, an ideal packet filter should discard spoofed packets while allowing valid packets to reach the destinations. For a packet filter, forwarding valid packets is more important than dropping invalid packets. We define the correctness of a packet filter as follows.
Definition 3 (Correctness of Packet Filtering): A packet filter is correct if it does not discard packets with valid source addresses when the routing system is stable.
Clearly, the route-based packet filtering is correct, because valid packets from source s to destination d will only traverse the edges on bestR(s, d) when the routing system is stable.
A. Motivating IDPFs
Although route-based packet filtering is correct, it requires each node to have the global knowledge of bestR(s, d). In the current Internet architecture that uses BGP as the inter-domain routing protocol, such information is not available. In BGP, route selection is a local decision, i.e., s computes bestR(s,d) based on the set of routes in its routing table and preferences that an operator in AS s has defined. This information may not be available at nodes in bestR(s,d). Consequently, route-based packet filtering cannot be applied in the current BGP-based Internet routing regime.
IDPF overcomes this problem by using the information implicit in BGP updates to construct the filters. We use the following concepts to illustrate the idea of IDPF. A topological route between nodes s and d is a loop-free path between the two nodes. Topological routes are implied by the network connectivity. A topological route is a feasible route under BGP if and only if the construction of the route does not violate the export rules imposed by the commercial relationship between ASes. Formally, let feasibleR(s, d) denote the set of feasible routes from s to d, then feasibleR(s, d) can be recursively defined as follows.

where ⊕ is the concatenation operation, e.g., {hs ⊕ {habi,huvi}} = {hsabi,hsuvi}. Notice that feasibleR(s, d) contains all the routes between the pair that does not violate the export policies r1-r4. Obviously, bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d). Each of the feasible routes can potentially be a candidate route in a BGP routing table. Theorem 1 also applies to feasible routes.
Definition 4 (Feasible Upstream Neighbor): Consider a feasible route r ∈ feasibleR(s, d). If an edge e(u, v) is on the feasible route, i.e., e(u, v) ∈ r.as path, we say that node u is a feasible upstream neighbor of node v for packet M(s, d). The set of all such feasible upstream neighbors of v (for M(s, d)) is denoted as feasibleU(s, v).
The intuition behind the IDPF framework is the following. First, it is possible for a node v to infer its feasible upstream neighbors using BGP route updates. The technique to infer feasible upstream neighbors is described in the next sub-section. Since bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d), a node can only allow M(s, d) from its feasible upstream neighbors to pass and discard all other packets. Such a filtering will not discard packets with valid source addresses. Second, although network connectivity (topology) may imply a large number of topological routes between a source and destination, commercial relationship between ASes and routing policies employed by ASes act to restrict the size of feasibleR(s, d). Consider the example in Fig. 1. Figs. 2(a) and (b) present the topological routes implied by network connectivity and feasible routes constrained by routing policies between sources and destination d, respectively. In Fig. 2(b) we assume that nodes a, b, c, and d have mutual peering relationship, and that a and b are providers to s. We see that although there are 10 topological routes between source

s and destination d, we only have 2 feasible routes that are supported by routing policies. Of more importance to IDPF is that, although network topology may imply all neighbors can forward a packet allegedly from a source to a node, feasible routes constrained by routing policies help limit the set of such neighbors. As an example, let us consider the situation at node d. Given that only nodes a and b (but not c) are on the feasible routes from s to d as node d concerns, node d can infer that all packets forwarded by node c and allegedly from source s are spoofed and should be discarded.
It is clear that packet filters based on feasible routes are less powerful than those based on best routes, given that bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d). On the other hand, AS relationships normally restrict the feasible routes between a pair of source and destination to a small set, which makes feasible-route based packet filtering a practical and promising approach against IP spoofing. In the following subsection, we will present a mechanism for each node to identify the set of feasible upstream neighbors that can forward packet M(s, d) to the node, based on locally exchanged BGP updates between the node and its immediate neighbors.
B. Constructing IDPFs
The following lemma summarizes the technique to identify the feasible upstream neighbors of node v for packet M(s, d).
Lemma 1: Consider a feasible route r between source s and destination d. Let v ∈ r.as path and u be the feasible upstream neighbor of node v along r. When the routing system is stable, export(u → v)[{bestR(u, s)}] 6= {}, assuming that all ASes follow the rules r1-r4 and that each AS accepts legitimate routes exported by neighbors.
Lemma 1 states that if node u is a feasible upstream neighbor of node v for packet M(s, d), node u must have exported to node v its best route to reach the source s.
Proof: Since Theorem 1 applies to feasible routes, a feasible route can be one of the six types of paths in Theorem 1. In the following we assume the feasible route r is of type (f), i.e., an uphill path followed by a peer-to-peer edge, which is followed by a downhill path. Cases where rhas other types (a)-(e) can be similarly proved. To prove the lemma, we consider the possible positions of nodes u and v in the feasible route.
Case 1: Nodes u and v belong to the uphill path. Then node s must be an (indirect) customer or sibling of node u. From Rule r1 and the definition of indirect customers/siblings, we know u will propagate to (provider) node v the reachability information of s. Case 2: e(u, v) is the peer-to-peer edge. This case can be similarly proved as case 1 (based on Rule r3). Case 3: Nodes u and v belong to the downhill path. Let e(x, y) be the peer-to-peer edge along the feasible route r, and note that u is an (indirect) customer of y. From the proof of case 2, we know that node y learns the reachability information of s from x. From Rule r2 and the definition of indirect customers, node y will propagate the reachability information of s to node u, which will further export the reachability information of s to (customer) node v.
It is critical to note that Lemma 1 only states that a feasible upstream neighbor u of neighbor v for packet M(s, d) exports to v its best route to reach source s. Node v may choose a node other than u to reach s. Therefore, Lemma 1 does not imply the symmetry of best routes. For example, although feasible route hs . . . uv . . . di may be the best route from s to d, route hd . . . vu . . . si may not be the best route from d to s.
Relying on Lemma 1, a node can identify the feasible upstream neighbors for packet M(s, d) and conduct interdomain packet filtering as follows. Note that the filters are defined at a node specific to each neighbor. Definition 5 (Inter-Domain Packet Filtering (IDPF)): Node v will accept packet M(s, d) forwarded by a neighbor node u, if and only if export(u → v)[{bestR(u, s)}] 6= {}. 3 Otherwise, the source address of the packet must have been spoofed, and the packet should be discarded by node v.
C. Correctness of IDPF
Theorem 2: An IDPF as defined in Definition 5 is correct. Proof: Without loss of generality, consider source s, destination d, and a node v ∈ bestR(s, d).as path such
As a technical detail, the condition should be import(v ← u)[export(u → v)[{bestR(u, s)}] 6= {}. That is, not only is bestR(u, s) is exported to v by u, but also accepted by v. However, for clarity of our presentation, we ignore the effects of import policies

that v deploys an IDPF filter. In order to prove the correctness of the theorem, we need to establish that v will not discard packet M(s, d) forwarded by the best upstream neighbor u, along bestR(s, d).
Recall from the best route selection process, the best route between a source and destination is also a feasible route between the two (bestR(s, d) ∈ candidateR(s, d) ⊆ feasibleR(s, d)). Therefore, u is also a feasible upstream neighbor of node v for packet M(s, d). From Lemma 1, u must have exported to node v its best route to source s. That is export(u → v)[{bestR(u, s)}] 6= {}. From Definition 5, packet M(s, d) forwarded by node u will not be discarded by v, and we have established the correctness of the theorem.
D. Routing Policy Complications
There is an increasing trend for ASes to be multi-homed to improve the overall reliability of their Internet connectivity. In some cases, it is desirable for a multi-homed AS to use one provider as the primary or preferred provider, and treat others as back-up providers. This is illustrated in Fig 3(a). Here, ASes a and b are the providers for AS d. Among these, d wishes to use a as the primary provider and use b as a backup provider. There are several different mechanisms to achieve this goal.
A particular way to achieve this is by using so-called BGP Conditional Advertisement or Selective Announcements, as depicted in Fig. 3(b). Here, AS d announces its routes to provider a (but not to b), causing all incoming traffic to arrive via a. If the primary route through a fails, AS d will send a route to provider b and this causes subsequent inbound traffic to arrive via b. When the original primary link is restored, d withdraws its route from b, causing traffic to switch back to arriving via a. Here, note that d does not announce its route(s) to b as long as the link to a is available. However, it may still use b to send outgoing traffic. If, in this situation, b deploys an IDPF, traffic from d will be blocked.
It is important to note that selective announcement is very different from the case where a route is prohibited by r1-r4. In the present case, d chooses not to export the route even though it is allowed to (within the guidelines defined in r1-r4). This behavior cannot be supported within the IDPF framework. To be consistent with IDPF, the AS can choose alternate methods to achieve the same goal, perhaps using AS path prepending (to make the route through b less preferred) or some BGP community attributes. A stronger case can be made for this by noting that the mechanism of selective announcements has undesirable side effects. Similarly, if an AS rejects alegitimate route to a prefix exported by a neighbor that follows rules r1-r4, IDPFs may drop packets from that prefix.
If for some reason, an AS u chooses to employ selective announcements, i.e., it chooses not to announce a route to a neighbor (even though it can under r1-r4), we suggest the following rule to be applied at u:
r5. Restricted conditional advertisement policy: If an AS can announce a route (originated by a specific network) to a neighbor, but chooses not to do so, then the AS must not forward any traffic from the network to the particular neighbor.
If each AS on the Internet follows the routing policies r1- r5, we can establish the correctness of IDPFs as defined in Definition 5 on the Internet. The proof is similar to the one of Lemma 1 and Theorem 2 and we omit it here.
V. PRACTICAL DEPLOYMENT ISSUES OF IDPFS
A. Incremental Deployment
From the description in Section IV, it should be clear that the IDPFs can be deployed independently in each AS. IDPFs are deployed at the border routers, so that IP packets can be inspected before they enter the network. We term border routers that are IDPF enabled as “IDPF nodes”. An IDPF node is required to track the destination network prefixes announced by each neighbor. Typically, we expect that BGP speaking routers will support IDPF. In the case that an IDPF node is not a BGP router, it needs to obtain the corresponding prefix announcement information from the BGP speaking routers.
When a packet arrives at an IDPF node, it needs to be associated with the specific neighbor that forwarded the packet. Subsequently, the IDPF matches the address against the set of prefixes announced by the specific neighbor. If a matching prefix exists, the packet is forwarded to the immediate destination in the AS or further routed towards the final destination. Otherwise, it is dropped by the IDPF node at the ingress of the network.
B. Handling Routing Dynamics
In the discussion so far, we have assumed that the AS graph is a static structure. However, in reality, the graph does change, triggering the generation of BGP updates and altering the paths that ASes use to reach each other. In this subsection, we examine how routing dynamics may affect the operation of IDPFs. We consider two different types of routing dynamics: 1) those caused by network failures; 2) and those caused by the creation of a new network (or recovery from a fail-down network event). Routing dynamics caused by routing policy changes can be similarly addressed and we omit them here.
Note that while filters are constructed based on route updates received from neighbors, they are completely oblivious to the specifics of the announced route. Moreover, the set of feasible upstream neighbors will not admit more members in the period of routing convergence following a network failure (since AS relationship is static). Hence, for the first type of routing dynamics, we can rule out the possibility that the filter will block a valid IP packet. We illustrate this as follows:
consider an IDPF enabled AS v that is on the best route from s to d. Let u = bestU(s, d, v), and let U = feasibleU(s, v). A link or router failure between u and s can have three outcomes: 1) AS u can still reach AS s, and u is still chosen to be the best upstream neighbor for packet M(s, d), i.e, u = bestU(s, d, v). In this situation, although u may explore and announce multiple routes to v during the path exploration process [7], the filtering function of v is unaffected. 2) AS u is no longer the best upstream neighbor for packet M(s, d); another feasible upstream neighbor u 0 ∈ U can reach AS s and is instead chosen to be the new best upstream neighbor (for M(s, d)). Now, both u and u 0 may explore multiple routes; however, since u 0 has already announced a route (about s) to v, the IDPF at v can correctly filter (i.e., accept) packet M(s, d) forwarded from u 0 . 3) No feasible upstream neighbors can reach s. Consequently, AS v will also not be able to reach s, and v will no longer be on the best route between s and d. No new packet M(s, d) should be sent through v.
Yet another concern of routing dynamics relates to how newly connected network (or a network recovered from a faildown event) will be affected. In general, a network may start sending data immediately following the announcement of a (new) prefix, even before the route has had time to propagate to the rest of the Internet. In the time that it takes for the route to be propagated, some packets (from this prefix) maybe discarded by some IDPFs if the reachability information has not yet propagated to them. However, the mitigating factor here is that in contrast to the long convergence delay that follows failure, reachability for the new prefix will be distributed far more speedily. In general, the time taken for such new prefix information to reach an IDPF is proportional to the shortest AS path between the IDPF and the originator of the prefix and independent of the number of alternate paths between the two. Previous work has established this bound to be O(L), L being the diameter of the AS graph [7], [22]. We believe that in the short timescales we are discussing, it is acceptable for IDPFs to potentially behave incorrectly, i.e. discarding valid packets originated from the new network prefix, before the corresponding BGP announcements reach the IDPFs. Similarly, during this short time of period, IDPFs may fail to discard spoofed attack packets. However, given that most DDoS attacks require a persistent train of packets to be directed at a victim, we believe this behavior of IDPFs for failing to discard spoofed packets should also be acceptable.
C. Other Issues
In the rest of this section we briefly discuss a few other properties of the IDPF framework.
By deploying IDPFs, an AS constrains the set of packets that a neighbor can forward to the AS. Specifically, a neighbor can only successfully forward a packet M(s, d) to the AS after it announces the reachability information of s. All other packets are identified to carry spoofed source addresses and discarded at the border router of the AS. In the worst case, even if only a single AS deploys IDPF and spoofed IP packets can get routed all the way to the AS in question, using an IDPF perimeter makes it likely that spoofed packets will be identified, and blocked, at the perimeter. Clearly, if the AS is well connected, launching a DDoS attack upon the perimeter itself takes a lot more effort than targeting individual hosts and services within the AS. In contrast, ASes that do not deploy IDPF offer relatively little protection to the internal hosts and services. Therefore, an AS has direct benefits to deploy IDPFs. In general, by deploying IDPFs, an AS can also protect other ASes to which the AS transports traffic, in particular, the customer ASes. This can be similarly understood that, an IDPF node limits the set of packets forwarded by a neighbor and destined for a customer of the AS.
The destination address d in a packet M(s, d) plays no role in an IDPF node’s filtering decision (Definition 5). We make this design decision for the following reasons: 1) We assume that a node u will forward a packet M(s, d) to node v only if bestR(v, d) has been exported to u by v. 2) By constructing filtering tables based on source address alone (rather than both source and destination addresses), per-neighbor space complexity for an IDPF node is reduced from O(N2 ) to O(N), where N = |V | is the number of nodes in the graph (the route-based scheme can achieve the same complexity bound.
An IDPF may not be able to catch all spoofed packets forwarded by a neighbor. Note that an IDPF allows all the feasible upstream neighbors for packet M(s, d) to send the packet. However, in reality, exactly one of them will lie on bestR(s, d) and forward M(s, d). On the other hand, it is worth noting that an attacker in a best upstream neighbor for packet M(s, d) can always spoof the source address s; therefore, route-based packet filters also cannot catch all spoofed packets. In the next section, we will conduct simulation studies to compare the performance of route-based packet filtering with that of the IDPF framework.
VI. PERFORMANCE STUDIES
In this section we first discuss the objectives of our performance studies and the corresponding performance metrics. We then describe the data sets and specific settings used in the simulation studies. Detailed results obtained from simulations are presented at the end of this section.
A. Objectives and Metrics
We evaluate the effectiveness of IDPFs in controlling IP spoofing based DDoS attacks from two complementary perspectives [29]. First, we wish to understand how effective the IDPFs are in proactively limiting (if not preventing) the capability of an attacker to spoof addresses of ASes other than his own. Our approach does not provide complete protection and spoofed packets may still be transmitted. Thus the complementary, reactive view is also important; we study how the deployed IDPFs can improve IP traceback effectiveness by localizing the actual source of spoofed packets. A third dimension of our simulation studies concerns the issue of incentive, i.e., how an individual AS will benefit from deploying IDPF on its routers.
A family of performance metrics was introduced in [29], and we include them in our own study. Given any pair of ASes, say a and t, Sa,t is the set of ASes, from which an attacker in AS a can forge addresses to attack t. For any pair of ASes, s and t, Cs,t is the set of ASes, from which attackers can attack t using addresses belonging to s, without such packets being filtered before they reach t.
To establish a contrast: Sa,t quantifies the pool of IP addresses that may be forged by an attacker in a to send packets to t without being stopped. On the hand, Cs,t is defined from the victim, i.e., AS t’s perspective. This quantifies the size of the set of ASes that can forge an address belonging to s in sending packets to t without being discarded along the way. Thus the latter is a measure of the effort required, at AS t, to trace the packets to the actual source (there are |Cs,t| locations that the packet could have originated from).
1) Proactive Prevention Metrics: Given the AS graph G = (V, E), we define the prevention metric from the point of view of the victim as follows:

φ1(τ ), redefined from [29], denotes the proportion of ASes that satisfy the following property: if an arbitrary attacker intends to generate spoofed packets, he can successfully use the IP addresses of at most τ ASes (note that this includes the attacker’s own AS). Thus, φ1(τ ) represents the effectiveness of IDPFs in protecting ASes against spoofing-based DDoS attacks. For instance, φ1(1), which should be read as the fraction of ASes that can be attacked with packets from at most 1 AS, describes the immunity to all spoofing based attacks.4 Next, we define a metric from the attacker’s perspective. Given G = (V, E), φ2(τ ), defined in [29], describes the fraction of ASes from which an attacker can forge addresses belonging to at most τ ASes (including the attacker’s own), in attacking any other ASes in the graph.

Intuitively, φ2(τ ) is the strength of IDPFs in limiting the spoofing capability of an arbitrary attacker. For instance, φ2(1) quantifies the fraction of ASes from which an attacker cannot spoof any address other than his own.
2) Reactive IP Trace back Metrics: To evaluate the effectiveness of IDPFs in reducing the IP trace back effort, i.e., the act of determining the true origin of spoofed packets, ψ1(τ ) is defined in, which is the proportion of ASes being attacked that can localize the true origin of an attack packet to be within τ ASes.

For instance, ψ1(1) is simply the fraction of ASes, which when attacked, can correctly identify the (single) source AS that the spoofed packet was originated from.
3) Incentives to Deploy IDPF: To formally study the gains that ASes might accrue by deploying IDPFs on their border routers, we introduce a related set of metrics, φ¯ 1(τ ), φ¯ 2(τ ), and ψ¯ 1(τ ). Let T denote the set of ASes that support IDPFs.
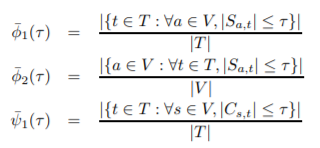
Note that these are similar to the metrics defined earlier, i.e., φ1(τ ), φ2(τ ), and ψ1(τ ), respectively. However, we restrict the destinations to the set of IDPF enabled ASes, rather than the entire population of ASes.
B. Data Sets
In order to evaluate the effectiveness of IDPFs, we construct four AS graphs from the BGP data archived by the Oregon Route Views Project [27]. The first three graphs, denoted G2003, G2004, and G2005 are constructed from single routing table snapshots (taken from the first day in each of the years). While these provide an indication of the evolutionary trends in the growth of the Internet AS graph, they offer only a partial view of the existing connectivity [17]. In order to obtain a more comprehensive picture, similar to [14], [18], we construct G2004c by combining G2003 and an entire year of BGP updates between G2003 and G2004. Note that the Slammer worm attack [25], which caused great churn of the Internet routing system, occurred during this period of time. This had the side effect of exposing many more edges and paths than would be normally visible.
Table II summarizes the properties of the four graphs. In the table we enumerate the number of nodes, edges, and AS paths that we could extract from the datasets. We also include the size of the vertex cover for the graph corresponding to individual datasets (the construction is described later). From the table we see that, G2004c has about 22000 more edges compared to G2004, or a 65.9% increase. Also, the number of observed AS paths in G2004c is an order of magnitude more than the observed paths in the G2004 data.
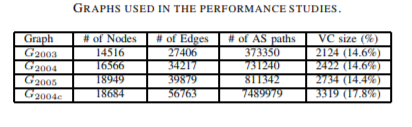
C. Inferring Feasible Upstream Neighbors
In order for each AS to determine the feasible upstream neighbors for packets from source to destination, we also

augment each graph with the corresponding AS paths used for constructing the graph [27]. We infer the set of feasible upstream neighbors for a packet at an AS as follows. In general, if we observe an AS path hvk, vk−1, . . . , v0i associated with prefix P, we take this as an indication that vi announced the route for P to vi+1, i.e., vi ∈ feasibleU(P, vi+1), for i = 0, 1, . . . , k − 1
D. Settings of Performance Studies
1) Routing: Given an AS graph G = (V, E) and a subset of nodes T ⊆ V deploying the IDPFs, the route that a packet takes from source node s to destination node t will determine the IDPFs that the packet will encounter on the way. Consequently, in order to compute the described performance metrics, we require the exact routes that will be taken between any pairs of nodes. Unfortunately, there is simply no easy way to get this knowledge accurately. In this paper, as a heuristic, we simply use the shortest path on G. When there are multiple candidates, we arbitrarily select one of them. Note that this knowledge, i.e., the best path from an AS to another, is only required in the simulation studies to determine the IDPFs that a packet may encounter on the way from source to destination. It is not required in the construction of the IDPFs. As a consequence, in addition to AS paths, we also include the selected shortest path as a feasible route, if it has not been described in the routing updates observed.
2) Selecting IDPF Nodes:
Given a graph G = (V, E), we select the filter set, i.e., nodes in T to support IDPF in one of two ways. The first one, denoted V C, aggressively selects the nodes with the highest degree until nodes in T form a vertex cover of G. In the second method, Rnd, we randomly (uniformly) choose the nodes from V until a desirable proportion of nodes are chosen. In the studies that we describe the target proportions are 30% and 50%. The corresponding sets are labeled Rnd30 and Rnd50, respectively.
3) BGP Updates vs. Precise Routing:
So far we have assumed that the precise global routing information is not available at IDPFs, and they rely on BGP update messages to infer if a packet originated from a prefix can be forwarded by a specific neighbor. To exactly understand any improvement we gain from accurate knowledge of the best route between ASes, we compare performance in two settings. In the first, BGP updates, ASes only use the AS paths (as described above) to construct the filters. In the second, precise routing, which is identical to the route-based packet filtering in, each node in the graph knows the best route for all other pairs and uses that single best route in the filter construction.
4) Network Ingress Filtering: Network ingress filtering is a mechanism that prevents an AS, where the mechanism is deployed, from being used to stage IP spoofing based attacks against host(s) in a different AS. It is reasonable to assume that ASes that deploy IDPFs, being security conscious and network-savvy, will also implement ingress filtering. However, this cannot always taken to be the case, and towards the end of this section, we discuss the case when ingress filtering is not deployed anywhere.
E. Results of Performance Studies
The studies are performed with the Distributed Packet Filtering (dpf) simulation tool . We extended dpf to support our own filter construction based on BGP updates. Before we describe the simulation results in detail, we briefly summarize the salient findings.
• Although it is difficult to completely protect networks from spoofing-based DDoS attacks (unless filters are near-universally deployed by ASes on the Internet), IDPFs can significantly limit the spoofing capability of an attacker. For example, with V C IDPF coverage, an attacker in more than 80% of ASes cannot successfully launch any spoofing-based attack on the Internet. Moreover, with the same configuration, the AS under attack can localize the true origin of an attack packet to be within 28 ASes, therefore, greatly reducing the effort of IP traceback.
• Network ingress filtering helps improve the performance of IDPFs. However, even without network ingress filtering being deployed in any ASes, an attacker still cannot launch any spoofing-based attacks from within more than 60% of ASes. Moreover, the AS under attack

can localize the true origin of an attack packet to be within 87 ASes.
ASes (and their customers) are better protected by deploying IDPFs compared to the ones that do not. For example, while only about 5% of all nodes on the Internet cannot be attacked by attackers that can spoof IP addresses of more than 6000 nodes, that percentage becomes higher than 11% among the nodes that support IDPFs (with Rnd30 IDPF coverage).
1) IDPFs with BGP Updates: Fig. 4(a) presents the values of φ1(τ ) for three different ways of selecting the IDPF node on the G2004c graph: vertex cover (V C) and random covers (Rnd50 and Rnd30). Note that φ1(τ ) indicates the proportion of nodes that may be attacked by an attacker that can spoof the IP addresses of at most τ nodes. In particular, φ1(1) is the portion of nodes that are immune to any spoofingbased attacks. Unfortunately, it is zero for all three covers. Moreover, as shown in Fig. 6, unless nearly all nodes support IDPFs, we cannot completely protect a network from spoofingbased attacks. (This is the case for all the simulations we conducted for this work.) As a consequence, instead of trying to completely protect ASes from spoofing-based attacks, we should focus on limiting the spoofing capability of attackers, which is indeed feasible as we shall show shortly. The figure also shows that the placement of IDPFs plays a key role in the effectiveness of IDPFs in controlling spoofing-based attacks. For example, with only 17.8% of nodes supporting IDPFs, VC outperforms both Rnd30 and Rnd50, although they recruit a larger number of nodes supporting IDPFs. In general, it is more preferable for nodes with large degrees (such as big ISPs) to deploy IDPFs. Fig. 5(a) shows φ1(τ ) for the graphs from 2003 to 2005 (including G2004c). We see that, overall, similar trends hold for all the years examined. However, it is worth noting that G2004c performs worse than G2004. This is because G2004c contains more edges and more AS paths by incorporating one-year BGP updates.
φ2(τ ) illustrates how effective IDPFs are in limiting the spoofing capability of attackers. In particular, φ2(1) is the proportion of nodes from which an attacker cannot launch any spoofing-based attacks against any other nodes. Fig. 4(b) shows that IDPFs are very effective in this regard. For G2004c, φ2(1) = 0.807857, 0.592325, 0.361539, for V C, Rnd50, and Rnd30, respectively. Similar trends hold for all the years examined (Fig. 5(b)).
Recall that ψ1(τ ) indicates the proportion of nodes that, under attack by packets with a source IP address, can pinpoint the true origin of the packets to be within at most τ nodes. Fig. 4(c) shows that all nodes can localize the true origin of an arbitrary attack packet to be within a small number of candidate nodes (28 nodes, see Fig. 5(c)) for the V C cover. For the other two, i.e., Rnd30 and Rnd50, the ability of nodes

to pinpoint the true origin is greatly reduced. From Fig. 5(c) we also see that G2003, G2004, and G2005 can all pinpoint the true origin of attack packets to be within 10 nodes. However, it is important to note that such graphs are less-complete representations of the Internet topology compared to G2004c.
2) Impacts of Precise Routing Information: In this section we study the impact of the precise global routing information on the performance of IDPFs. As shown in Fig. 7, the availability of the precise routing information between any pair of source and destination only slightly improves the performance of IDPFs in comparison to the case where BGP update information is used. For example, while about 84% of nodes cannot be used by attackers to launch any spoofing-based attacks by relying on the precise routing information, there are still about 80% of ASes where an attacker cannot launch any such attacks by solely relying on BGP update information. Similarly, by only relying on BGP update information, an arbitrary AS can still pinpoint the true origin of an attack packet be within 28 ASes, compared to 7 if precise global routing information is available.
ble for the slow deployment of network ingress filtering is that the deployment of such filtering function directly benefits the rest of the Internet instead of the network that supports it. In contrast, networks supporting IDPFs are better protected than the ones that do not (Fig. 8). In Fig. 8(a) we show the values of φ¯ 1(τ ) (curve marked with IDPF Nodes) and φ1(τ ) (marked with All Nodes). From the figure we see that while only about 5% of all nodes on the Internet cannot be attacked by attackers that can spoof IP addresses of more than 6000 nodes, that percentage increases to higher than 11% among the nodes that support IDPFs. Moreover, as the value of τ increases, the difference between the two enlarges. Similarly, while only about 18% of all nodes on the Internet can pinpoint the true origin of an attack packet to be within 5000 nodes, more than 33% of nodes supporting IDPFs can do so (Fig. 8(b)).
compares the spoofing capability of attackers in attacking a general node on the Internet and that supporting IDPFs. We see that networks supporting IDPFs only gain slightly in this perspective. This can be understood by noting that, by deploying IDPFs, an AS not only protects itself, but also those to whom the AS transports traffic.
4) Impacts of Network Ingress Filtering: So far we have assumed that networks supporting IDPFs also employ network ingress packet filtering [16], i.e., attackers cannot launch spoofing-based attacks from within such networks. In this section we examine the implications of this assumption.

From Fig. 12 we see that ingress packet filtering has only modest impacts on the effectiveness of IDPFs in limiting the spoofing capability of attackers. For example, without network ingress filtering, we still have more than 60% of nodes from which an attacker cannot launch any spoofing-based attacks, compared to 80% when ingress filtering is enabled at nodes supporting IDPFs. As shown in Fig. 13, the impact of networkingress filtering on the effectiveness of IDPFs in terms of reactive IP traceback is also small. Without ingress filtering, an arbitrary node can pinpoint the true origin of an attack packet to be within 87 nodes, compared to 28 when networks supporting IDPFs also employ ingress filtering.
VII. CONCLUSION AND FUTURE WORK
In this paper we proposed and studied an inter-domain packet filter (IDPF) architecture as an effective countermeasure to the IP spoofing-based DDoS attacks. IDPFs rely on BGP update messages exchanged between neighboring ASes on the Internet to infer the validity of source address of a packet forwarded by a neighbor. We showed that IDPFs can be easily deployed on the current BGP-based Internet routing architecture. Our simulation results showed that, even with partial deployment on the Internet, IDPFs can significantly limit the spoofing capability of attackers; moreover, they also help localize the actual origin of an attack packet to be within a small number of candidate networks. In addition, IDPFs also provide adequate local incentives for network operators to deploy them. As future work, we plan to study the cost introduced by the filtering function on the forwarding path of packets. We also plan to investigate how other AS relationship and routing information may help to further improve the performance of IDPFs.

Comments
Post a Comment